Fulljoin

Usando o R no VS Code
Neste post detalhamos como configurar o VS Code para uso do R.
Extraindo dados das suas notas de corretagem em compra e venda de ações com R
Neste post mostramos como ler e extrair informações de uma nota de corretagem (padrão SINACOR) no R.

Testes estatísticos z e t
Por meio de exemplos hipotéticos e partindo do pressuposto de que as condições para a validade dos testes estatísticos são atendidas, mostramos, neste post, como aplicar dois testes estatísticos simples: o teste z e o teste t.

Criando base de dados com as atas do Copom
Nesse post vamos apresentar um script simples para obter os textos de todas as atas do Comitê de Política Monetária (Copom) e criar uma base pronta para exploração e análise textual

Prevendo a qualidade de vinhos com o tidymodels
O objetivo principal deste post é apresentar o tidymodels, uma coleção de pacotes para modelagem e aprendizado de máquina que utilizam os princípios do tidyverse. Para isso, iremos utilizar uma base de dados de qualidade de vinhos e implementar modelos de classificação.
Usando o Pytorch no R: Treinando o Seefood
Neste post iremos testar o uso do Pytorch no R com o auxílio do pacote reticulate, que permite a utilização de bibliotecas do Python diretamente no R. Isso ajuda a evitar (em parte) aquela disputa entre o R e o Python, uma vez que você pode usar o melhor de cada. Como exemplo, iremos treinar uma classificador de imagens que é a base do aplicativo Seefood que fez fama no seriado Silicon Valley da HBO.
Manipulação de texto com stringr - parte IV
Na quarta parte da série de posts sobre manipulação de texto com stringr veremos como usar funções um pouco mais técnicas. Também discutimos o caso da função case_when do dplyr que pode ser bastante útil ao se trabalhar com texto.

NBSVM com o Keras no R: Classificando Análises de Filmes (IMBd)
Neste post será mostrado como um classificador de sentimentos pode ser treinado utilizando o Keras no R. A nossa aplicação é baseada no modelo que ficou conhecido por NBSVM. Apesar de simples e de rápido treinamento, o nosso modelo atingiu uma acurácia de mais de 92% na base de teste. O estado da arte para esse problema é de 97,4%.

Problemas com memória ou tempo de execução no dplyr? Use o data.table
O objetivo deste post é apresentar como utilizar o pacote data.table por meio de uma "tradução" das operações realizadas com o dplyr. Para um entendimento completo deste post, é importante que o leitor tenha uma boa noção de como o dplyr funciona.
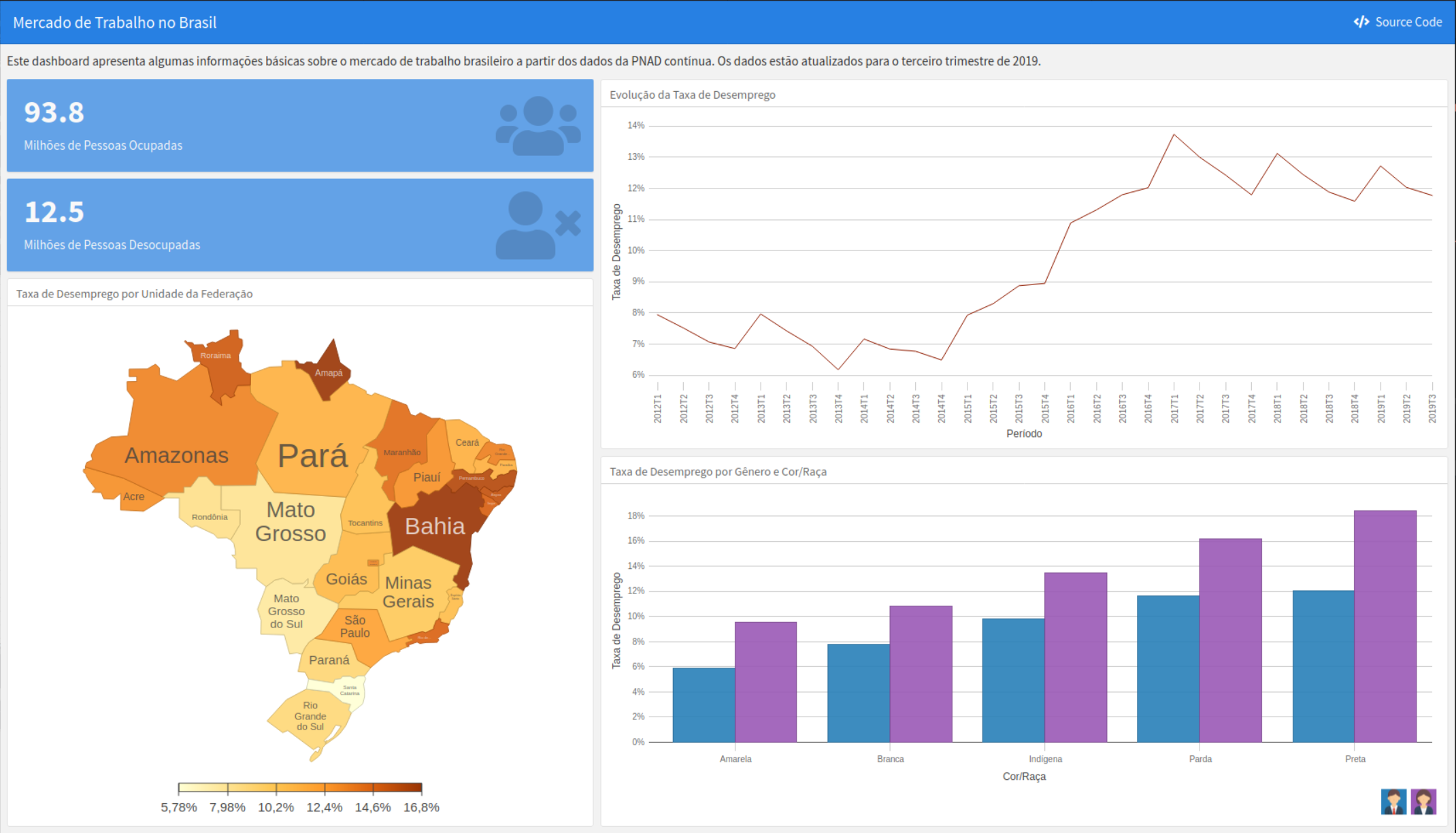
Dashboards no R com o pacote flexdashboard
Dashboards podem ser uma ferramenta eficiente para a fase de comunicação de uma análise de dados. No R, pode-se utilizar o pacote `flexdashboard` para a criação de dashboards de maneira rápida. Neste post, vamos falar sobre como funciona esse pacote e criaremos um exemplo com os dados da PNAD contínua e com o pacote `D3plusR` para elaboração das visualizações.

Diferentes sintaxes para manipulação de dados em R - parte 1
Nesse post vamos comparar diferentes pacotes com diferentes sintaxes e performances para explorar uma das principais tarefas sempre presentes na manipulação de dados: cruzamento de dados ou joins
Manipulação de texto com stringr - parte III
Na terceira parte da série de posts sobre manipulação de texto com stringr veremos como usar funções que removem padrões encontrados no texto, que substituem padrões por outros e que eliminam espaços de formas diferentes. Também aprofundaremos com um pouco mais de regex.

Entendendo os benefícios da paralelização usando Random Forest
O objetivo principal deste post é apresentar como utilizar a paralelização no R e os ganhos de eficiência ao utilizá-la. Para mostrar este processo, um problema de classificação usando o modelo Random Forest (em português, Floresta Aleatória) é utilizado.
Manipulação de texto com stringr - parte II
Este post continua a explorar funções úteis na manipulação de texto. Mais especificamente, iremos aprender a passar todas as letras de dados textuais para caixa baixa ou caixa alta. Também aprenderemos a capitalizar a primeira letra de cada palavra. Ademais, iremos ver algumas noções básicas de regex associadas ao uso da função str_detect.
Tidytext e Modelagem de Tópicos com o R: Analisando os Textos de Acordos Comerciais
Neste post, vamos fazer uma análise de tópicos utilizando os pacotes tidytext e topicmodels. Essa análise consiste em extrair um conjunto de temas (tópicos) de um conjunto de textos. Para isso, utilizamos uma base de textos de acordos comerciais. Veremos que o método utilizado é capaz de identificar uma séria de tópicos relevantes.
Manipulação de texto com stringr
Este é o post inicial de uma série de posts que faremos sobre manipulações de texto com o pacote stringr. Iremos criar alguns problemas e mostrar quais funções do pacote devemos utilizar para solucionar esses problemas. Aprenderemos a limpar os dados e a padronizá-los. Se você tem dificuldade com manipulação de texto, esse post é para você.

Avaliando sua carteira: Explorando dados financeiros com R - parte 3
Nesse poste vamos baixar nossa carteira do CEI, baixar as cotações históricas e testar um método de comparação do rendimento diário acumulado com um benchmark.

Por que evitar for loops em R?
A partir de um simples exemplo, vamos testar o desempenho de for loops comparando-o com a performance de outras alternativas como apply, funções do purrr e estratégias paralelizadas.

R com Excel
Neste post mostramos como criar arquivos Excel a partir do R.

CEI + rvest: Explorando dados financeiros com R - parte 2
Com o pacote rvest você pode baixar todo seu histórico de compra e venda de ações diretamente do CEI e passar a gerenciar sua carteira pelo R

Hello World - TensorFlow V2
Com a ajuda do pacote `tensorflow`, vamos replicar os códigos de exemplos iniciais do TensorFlow V2, que é a segunda versão da biblioteca de *machine learning* do Google. Apesar dos códigos originais estarem em Python, é fácil convertê-los para R. Nesse post, veremos como.

B3 + rvest: Explorando dados financeiros com R - parte 1
Primeiro de uma sequência de posts onde vamos utilizar o R para explorar dados financeiros disponíveis na internet. Aprofundaremos bastante em web scraping e manipulação de dados.

Analisando dados da guerra comercial - Parte 2
Nesta segunda parte, vamos aprofundar um pouco a nossa análise inicial. Realmente as sobretaxas impostas pelos Estados Unidos a produtos chineses não tiverem efeitos prático? Utilizando dados mensais que compreendem o período de janeiro de 2012 até maio de 2019, encontramos evidências dos seus efeitos. As estimativas indicam um nível de importação, em média, 20% menor para os produtos chineses sujeitos a sobretaxas.

Tradução de dados textuais com googleLanguageR
O pacote googleLanguageR utiliza o serviço de API do Google Tradutor e nos permite traduzir textos automaticamente.

Analisando dados da guerra comercial com o comtradr
Neste post iremos fazer uma breve apresentação sobre o pacote comtradr. Este pacote permite importar dados de comércio exterior do Comtrade diretamente pelo R, utilizando a API fornecida pelo portal das Nações Unidas. Utilizamos os dados para uma breve análise sobre a Guerra Comercial.

R e Rstudio - Dicas
Dicas úteis - R e Rstudio (Windows)

Scraping de dados da CBF com rvest
Nesse post apresentaremos um tutorial básico de web scraping utilizando o pacote rvest para extrair dados de jogos divulgadas no site da CBF. Rvest é um pacote do R que simplifica muito tarefas de scraping e te ajuda a extrair dados HTML das páginas web.

Estamos de volta!
Depois de muito tempo sem nenhuma atualização, estamos revivendo o Fulljoin!

Treinando um Classificador de Raças de Cães utilizando o Keras e Modelos Pré-Treinados
Neste post, iremos treinar uma classificador de raças de cães usando o pacote Keras e modelos pré-treinados no R. O código pode ser facilmente adaptado para problemas similares.

Classificando Comentários Tóxicos com o R
Nesse post, vamos criar um classificador de comentários tóxicos a partir de uma base de dados disponibilizada em uma competição do Kaggle. Serão utilizadas técnicas chamadas de bag-of-words e tf-idf.

Introdução ao D3plusR
Visualização de dados é uma das principais tarefas de um analista de dados. A partir de visualizações, é possível explorar os dados e comunicar resultados de maneira mais efetiva. No R, além de visualizações estáticas, principalmente desenvolvidas com ggplot2 R, existem um conjunto de pacotes que são desenvolvidos utilizando o _framework_ fornecido pelo pacote `htmlwidgets`. A ideia é trazer o mundo de bibliotecas de visualizações de dados em javascript para o R.

Bases de Dados Públicas - Kaggle
Durante o processo de aprendizagem de análise de dados é fundamental aplicar os conhecimentos adquiridos aos dados. Todavia, muitas vezes nos vemos obrigados a trabalhar com dados de exemplos que não apresentam as dificuldades do mundo real ou não guardam nenhuma relação com os dados que serão enfrentados no dia a dia. Nesse sentido, a possibilidade de acesso a outras base de dados pode ser bastante útil.

Visualização de dados - Parte 1: Introdução ao ggplot2
A visualização de dados é parte fundamental do [_workflow_]({{root_url}}/blog/2016/03/14/como-aplicar-ciencia-de-dados/) de um analista de dados. Essa tarefa é muito importante tanto para explorar os dados, como para comunicar resultados. Ou seja, dominar ferramentas de visualização é imprescindível. E é aí que entra o ggplot2.

Manipulação de dados - Parte 1: dplyr básico
Dominar a manipulação de dados é uma das habilidades mais básicas que um analista de dados deve ter. Nesse post ensinaremos as principais atividades relacionadas a manipulação de dados utilizando o pacote dplyr, um dos melhores pacotes disponíveis no R para essa finalidade.

Comex Vis e a visualização de dados no Brasil
No dia 28/07/2016 a Secretaria de Comércio Exterior lançou o [Comex Vis](http://www.mdic.gov.br/comercio-exterior/estatisticas-de-comercio-exterior/comex-vis), uma ferramenta de visualização interativa de dados do comércio exterior brasileiro. Nesse post faremos alguns comentários sobre o Comex Vis e sobre a visualização de dados em geral.

Introdução a Modelos no R
Neste post, vamos introduzir alguns conceitos para começar a trabalhar com modelos no R. Abordaremos o modelo linear de regressão utilizando a função `lm()`. Aprender a estrutura básica de modelos a partir do modelo linear será bastante útil para entender e utilizar outros modelos mais complexos.
Tudo sobre Joins (merge) em R
Nessa sequência de posts aprenderemos tudo sobre Joins (merges) em R, abordando questões teóricas e práticas, com exemplos usando R base e o pacote dplyr. Após ler esse post, você vai saber o que é, para que serve, quando e como usar diversos tipo de joins.
Kit de sobrevivência em R - Parte 7: Avançando e Aprofundando
Chegamos ao fim do [kit de sobrevivência em R]({{root_url}}/blog/categories/introducao-ao-r). Nesse último post da série vamos retomar alguns pontos que merecem ser complementados e revisados, além de apresentar um pouco mais de transformações e operações usando apenas funções básicas do R.

Kit de sobrevivência em R - Parte 6: Estruturas de Controle
No último post, você aprendeu um pouco sobre os tipos de dados e como realizar algumas transformações. Neste post, trataremos um pouco sobre estruturas de controles (for, if, else, while etc.). Estruturas de controles serão bastante usadas durante o processo de análise de dados, sendo importante que você domine esse tópico.
Kit de sobrevivência em R - Parte 5: Tipos de dados e transformações
Você já aprendeu como carregar um arquivo de dados no R para começar a trabalhar com ele. Agora vamos conhecer o básico necessário para manipular os dados e prepará-los para a análise propriamente dita. Para isso será necessário saber sobre alguns tipos básicos de dados e algumas formas de transformação de dados.
Kit de sobrevivência em R - Parte 4: Carregando Dados
Seguindo a sequência do *Kit de sobrevivência em R*, vamos abordar um pouco sobre uma das partes iniciais de qualquer análise ou trabalho que vá ser feito no R: carregamento e leitura de dados. Nesse post você irá aprender formas básicas de carregar dados e começar os trabalhos.
Kit de Sobrevivência em R - Parte 3: Pacotes
Neste post, você aprenderá um pouco sobre os pacotes, trabalhará com o console para fazer algumas operações e ir se familiarizando mais com o R. Aprenderá como usar as funções disponíveis no R e as funções adicionais em pacotes.
Kit de sobrevivência em R - Parte 2: Operações, Variáveis e Funções
Seguindo a proposta da sequência *Kit de sobrevivência em R*, vamos aprofundar um pouco mais no funcionamento do R e como fazer uso disso. Nesse post trataremos sobre comandos de console, operações básicas, variáveis, funções, e script R no editor de códigos.
Kit de sobrevivência em R - Parte 1: Visão Geral e Instalação
Nesta sequência de posts, iremos tratar o básico necessário para quem deseja iniciar o aprendizado em [R](https://www.r-project.org/about.html). Trata-se de uma linguagem de programação muito usada para cálculos estatísticos. Neste e nos próximos posts, discutiremos tópicos como instalação, importação de dados, tipos de dados, etc. A nossa expectativa é que, com essa sequência, seja quebrada a barreira inicial para aqueles que pretendem entrar nesse mundo.
Aplicando ciência de dados - parte 2: Equipe
Para aplicação da Ciência de Dados em um projeto, não basta ter uma ótima fonte de dados disponível e os melhores equipamentos e ferramentas prontos para uso. É necessário uma equipe.
Aplicando ciência de dados - parte 1: Workflow
No geral, atividades envolvendo aplicação da ciência de dados assumem o formato de projeto: empreendimentos de esforços durante um tempo (início e fim), usando recursos (pessoas e ferramentas) para alcançar um objetivo específico.
Hello World
E nasce hoje o Full Join! Um blog sobre data science e tudo mais que envolve a arte de trabalhar com dados. A ideia é postar sobre programação, estatística, machine learning e análise de dados, buscando consolidar nosso conhecimento e ajudar quem está começando (ou evoluindo!) na carreira de Cientista de Dados.